[This is written for the very few people who will ever try to do something like this this, and will Google for an explanation.]
I'd say this was harder than I imagined, but really I knew it would be bad. The reasons it's bad are the same reasons that medical software seems to be stuck in the 1980s.
The problem of reconciling data models and data capabilities is a much harder problem than relatively trivial tasks like natural language processing, speech recognition, syntax specifications, quantum computing, and developing multiprocessor compilers. The more knowledge a system contains, the more difficult it becomes to reconcile different semantics.
That's why loss-free interoperability of complex healthcare software is always ten years away.
It doesn't help that the problem is either unrecognized or underestimated.
Ok, I digress. The problem I had to solve was far simpler, though it was a large part of why Palm went from a growing billion dollar company to near bankruptcy.
I had to reconcile several address book data models.
Over several years platform migrations and a 2003 synchronization screwup had scattered my personal contact information between the PalmOS, FileMaker Pro 8 (Windows/OS X) and Microsoft Outlook. (My corporate contacts in a different Outlook 2003/Exchange environment [1].)
I needed to merge the information into a single data management environment, identify duplicates and conflicts, and create a reconciled view.
The first step was to figure out which environment to use. FileMaker Pro 8 has far better layout and user interface capabilities than Access 2003, but I'm regrettably very familiar with
Microsoft Access 2003 queries and data transformation. More importantly, until I switch to an iPhone, the true home of this data is in my
Palm Tungsten E/2 and
Microsoft Outlook 2003 (
synchronized).
Reconciliation had to occur in Access 2003.
The next step was to identify what fields to use (which data model, and, more abstractly, which semantic model), which data types, etc. I had to find something that could work across all these environments, and which would allow me to port data from the rich FileMaker environment.
It took me almost a half-day of work - my New Years Day resolution project. I'll summarize just the key points here for anyone who wants to do something like this, followed by a review of the final table structure (single table). The various matching algorithms and data updates turned out to be simpler than I'd expected.
- Outlook 2003's internal data model is probably not a relational model. In theory one can create a data link from Access 2003 to Outlook 2003, but this link exposes only a small portion of Outlook's contact data. The export to file/Access works best, omitting only a few odd fields.
- I think (though a lot was happening at this point) that Outlook will export and import a Contacts field (column) called "Keywords". Oddly enough, it's not accessible in the Outlook GUI! Ignore it.
- Outlook import is more limited than export. In particular, Outlook uses different column labels for import and export. Mostly it matches them despite the name changes (hidden mapping), but it fails to match "email" to "E-mail".
- The best connection to FileMaker is ODBC. I experimented both directions, but ended up using FileMaker as an ODBC server and Access as a client. This requires setting up FileMaker 8's weird ODBC services -- I think this is easier in later versions of FM.
- Access maps FM fields via ODBC to Memo fields. I did a full import and changed all but Notes to Text (255 character UTF-8).
- Some of the data I imported from either Outlook or FileMaker had empty not NULL columns in Access. I resolved this by finding all values that were not NULL but had a string length of 0, then I set them to NULL.
- Some FM and Outlook text data contained carriage returns. Outlook 2003 has a lot of trouble with these. I had to replace the CRs with spaces using an obscure technique.
- FileMaker hides its internal row identifiers, but I exposed them using Get(RecordID) ans stored them in my new database. (Access doesn't even have these, Oracle does. Longstanding complaint about Access.)
- Palm allows four "User fields". Outlook has 8 "custom fields", but not all of them are easy to get at. I used three "User fields" mapped to 3 "custom fields". In Palm Contact Options I name them (see below).
- Outlook import will only manage text, memo and date types.
This screenshot (click to enlarge) shows the fields in the reconciliation Access 2003 database. I've never figured out how to get a useful report on these things -- most databases allow one to write queries against internal metadata/schemas but Access doesn't. This was the best I could easily do:
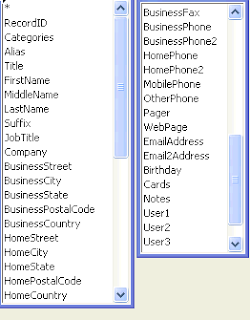
Keeping track of the identifiers is obviously important. RecordID is an Access 2003 Autonumber field. I store an Access Autonumber Synch identifier (a GUID) and a legacy FileMaker identifier in two fields accidentally omitted from the screenshot (sorry).
User1 - User3 contain keywords, date revised and a text data type copy of the Access record id.
--
[1] I am the only person on earth who wants to synchronize my work data to a unified device/platform but not synch my personal data to work. This is proof that I'm an alien.
Update 5/19/09: With my new
hacked together setup, I can use Access to manipulate Outlook and have the changes reflected through MobileMe to OS X Address Book to my iPhone.



